Voicebox
Discover Voicebox by Meta AI, a groundbreaking generative AI model for speech synthesis, offering multilingual capabilities, noise removal, and content editing.

Sarah Jane, with her unique blend of communication and computer science expertise, has quickly become an indispensable fact-checker and social media coordinator at PopularAITools.ai, ensuring content accuracy and engaging online presence in the fast-evolving AI tools & technology landscape.
Unleash the Power of Voice: Introducing Voicebox by Meta AI
Revolutionize your audio experience with Voicebox, the cutting-edge generative AI model for speech synthesis.
In an era where technology is constantly evolving, Meta AI has made a groundbreaking advancement in the realm of speech synthesis. Introducing Voicebox, the first generative AI model that is not only capable of creating high-quality audio clips but also excels in generalizing across various speech-generation tasks. Whether you're looking to synthesize speech in multiple languages, remove noise from audio, or convert styles, Voicebox is your go-to solution.

How Does Voicebox Work?
Voicebox is built on a novel method called Flow Matching. Unlike traditional speech synthesizers, which require specific training for each task, Voicebox learns from raw audio and its accompanying transcription. This enables it to modify any part of a given sample, not just the end of an audio clip. Voicebox is trained with over 50,000 hours of recorded speech and transcripts from public domain audiobooks in six languages: English, French, Spanish, German, Polish, and Portuguese.

Key Features and Benefits of Voicebox
- Multilingual Capabilities: Voicebox can synthesize speech across six languages.
- Noise Removal: It can seamlessly edit segments within audio recordings, resynthesizing portions of speech corrupted by short-duration noise.
- Content Editing: Voicebox can replace misspoken words without having to re-record the entire speech.
- Style Conversion: It can produce readings of text in different languages and styles.
- Diverse Sample Generation: Having learned from diverse data, Voicebox can generate speech that is more representative of how people talk in the real world.
- Speed and Efficiency: Voicebox is up to 20 times faster than the current state-of-the-art models.
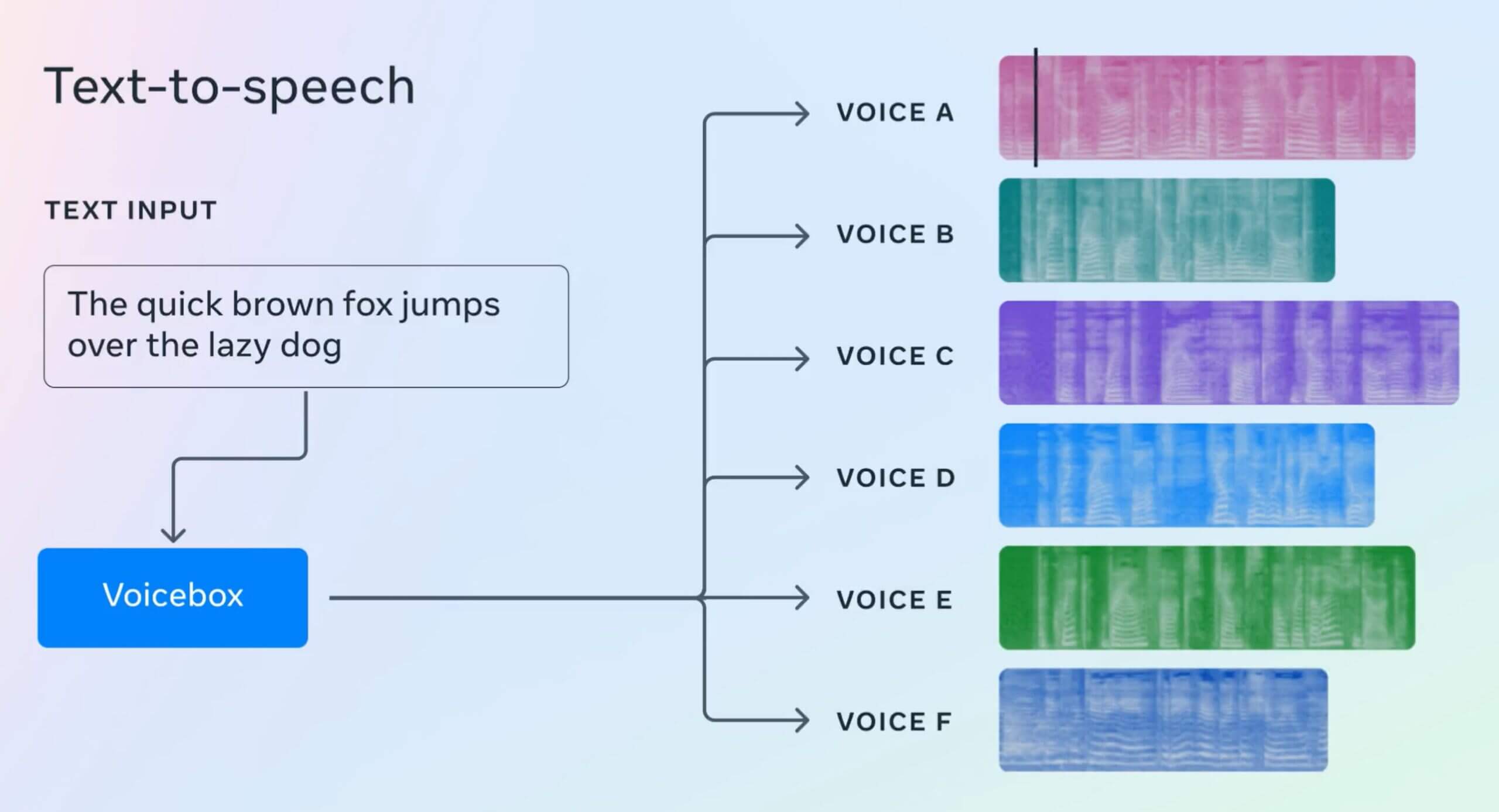
Voicebox Use Cases
- In-context Text-to-Speech Synthesis: Voicebox can match the audio style of a short input sample and use it for text-to-speech generation.
- Cross-lingual Style Transfer: Produce readings of text in different languages with the same style.
- Speech Denoising and Editing: Clean up and edit audio recordings effortlessly.
- Diverse Speech Sampling: Generate synthetic data for training speech assistant models.
What Problem Does Voicebox Solve?
Voicebox addresses the limitations of existing speech synthesizers that can only be trained on data prepared for specific tasks. It offers versatility, efficiency, and generalization across tasks, making it ideal for a wide range of applications including text-to-speech synthesis, audio editing, and cross-lingual communication.

Voicebox Pricing and Availability
As of now, Meta AI has not made Voicebox publicly available due to potential risks of misuse. However, they have shared audio samples and a research paper detailing the approach and results achieved with Voicebox.

Who Should Use Voicebox?
Voicebox is ideal for:
- Content Creators: For editing and enhancing audio content.
- Multilingual Communicators: For seamless communication across languages.
- Accessibility Services: To bring speech to people who are unable to speak.
- AI Developers: For generating synthetic data to train speech assistant models.
This product description review provides an in-depth look at Voicebox, a state-of-the-art generative AI model for speech synthesis developed by Meta AI. With its remarkable features and benefits, Voicebox is set to revolutionize the audio domain. Whether you are a content creator, a multilingual communicator, or someone looking to enhance accessibility services, Voicebox is the ultimate tool for all your audio needs.
Frequently Asked Questions - FAQ's
What is Voicebox?
Voicebox is a groundbreaking generative AI model developed by Meta AI. It is designed for speech synthesis and is capable of generalizing across various speech-generation tasks. Unlike traditional speech synthesizers, Voicebox can create high-quality audio clips in multiple languages, perform noise removal, content editing, and style conversion.
How does Voicebox differ from traditional speech synthesizers?
Traditional speech synthesizers require specific training for each task and can only be trained on data that has been prepared expressly for that task. Voicebox, on the other hand, uses a novel method called Flow Matching and learns from raw audio and its accompanying transcription. This enables it to modify any part of a given sample and perform well across a variety of tasks.
In which languages can Voicebox synthesize speech?
Voicebox is capable of synthesizing speech in six languages: English, French, Spanish, German, Polish, and Portuguese.
What is Flow Matching and how does it contribute to Voicebox's capabilities?
Flow Matching is a method upon which Voicebox is built. It is an advancement on non-autoregressive generative models that can learn highly non-deterministic mapping between text and speech. This enables Voicebox to learn from varied speech data without the variations having to be carefully labeled. As a result, Voicebox can train on more diverse data and on a much larger scale.
Can Voicebox be used for audio editing?
Yes, Voicebox is capable of audio editing. Its in-context learning makes it adept at generating speech to seamlessly edit segments within audio recordings. It can resynthesize portions of speech corrupted by short-duration noise or replace misspoken words without having to re-record the entire speech.
What are the potential applications of Voicebox?
Voicebox has a wide range of applications including in-context text-to-speech synthesis, cross-lingual style transfer, speech denoising and editing, and diverse speech sampling. It can be used by content creators for audio editing, by multilingual communicators for seamless communication across languages, and in accessibility services to bring speech to people who are unable to speak.
Is Voicebox available for public use?
As of the information provided in the blog post, Meta AI has not made Voicebox publicly available due to potential risks of misuse. However, they have shared audio samples and a research paper detailing the approach and results achieved with Voicebox.
How does Voicebox handle the potential risks of misuse?
Meta AI recognizes the potential for misuse and unintended harm with Voicebox. They have built a highly effective classifier that can distinguish between authentic speech and audio generated with Voicebox to mitigate possible future risks.
Can Voicebox be used to generate synthetic data for training speech assistant models?
Yes, having learned from diverse in-the-wild data, Voicebox can generate speech that is more representative of how people talk in the real world. This capability can be used to generate synthetic data to help better train speech assistant models.
Where can I listen to samples of audio generated by Voicebox?
Meta AI has shared audio samples of Voicebox on their website. You can listen to the samples by visiting the official Voicebox page.
These FAQs provide a comprehensive understanding of Voicebox, its capabilities, applications, and availability. Voicebox represents a significant advancement in speech synthesis and has the potential to revolutionize the audio domain.
Share On Socails
Trending AI Tools

What’s a Rich Text element?
The rich text element allows you to create and format headings, paragraphs, blockquotes, images, and video all in one place instead of having to add and format them individually. Just double-click and easily create content.
Static and dynamic content editing
A rich text element can be used with static or dynamic content. For static content, just drop it into any page and begin editing. For dynamic content, add a rich text field to any collection and then connect a rich text element to that field in the settings panel. Voila!
How to customize formatting for each rich text
Headings, paragraphs, blockquotes, figures, images, and figure captions can all be styled after a class is added to the rich text element using the "When inside of" nested selector system.
Unleash the Power of Voice: Introducing Voicebox by Meta AI
Revolutionize your audio experience with Voicebox, the cutting-edge generative AI model for speech synthesis.
In an era where technology is constantly evolving, Meta AI has made a groundbreaking advancement in the realm of speech synthesis. Introducing Voicebox, the first generative AI model that is not only capable of creating high-quality audio clips but also excels in generalizing across various speech-generation tasks. Whether you're looking to synthesize speech in multiple languages, remove noise from audio, or convert styles, Voicebox is your go-to solution.
How Does Voicebox Work?
Voicebox is built on a novel method called Flow Matching. Unlike traditional speech synthesizers, which require specific training for each task, Voicebox learns from raw audio and its accompanying transcription. This enables it to modify any part of a given sample, not just the end of an audio clip. Voicebox is trained with over 50,000 hours of recorded speech and transcripts from public domain audiobooks in six languages: English, French, Spanish, German, Polish, and Portuguese.
Key Features and Benefits of Voicebox
- Multilingual Capabilities: Voicebox can synthesize speech across six languages.
- Noise Removal: It can seamlessly edit segments within audio recordings, resynthesizing portions of speech corrupted by short-duration noise.
- Content Editing: Voicebox can replace misspoken words without having to re-record the entire speech.
- Style Conversion: It can produce readings of text in different languages and styles.
- Diverse Sample Generation: Having learned from diverse data, Voicebox can generate speech that is more representative of how people talk in the real world.
- Speed and Efficiency: Voicebox is up to 20 times faster than the current state-of-the-art models.
Voicebox Use Cases
- In-context Text-to-Speech Synthesis: Voicebox can match the audio style of a short input sample and use it for text-to-speech generation.
- Cross-lingual Style Transfer: Produce readings of text in different languages with the same style.
- Speech Denoising and Editing: Clean up and edit audio recordings effortlessly.
- Diverse Speech Sampling: Generate synthetic data for training speech assistant models.
What Problem Does Voicebox Solve?
Voicebox addresses the limitations of existing speech synthesizers that can only be trained on data prepared for specific tasks. It offers versatility, efficiency, and generalization across tasks, making it ideal for a wide range of applications including text-to-speech synthesis, audio editing, and cross-lingual communication.
Voicebox Pricing and Availability
As of now, Meta AI has not made Voicebox publicly available due to potential risks of misuse. However, they have shared audio samples and a research paper detailing the approach and results achieved with Voicebox.
Who Should Use Voicebox?
Voicebox is ideal for:
- Content Creators: For editing and enhancing audio content.
- Multilingual Communicators: For seamless communication across languages.
- Accessibility Services: To bring speech to people who are unable to speak.
- AI Developers: For generating synthetic data to train speech assistant models.
This product description review provides an in-depth look at Voicebox, a state-of-the-art generative AI model for speech synthesis developed by Meta AI. With its remarkable features and benefits, Voicebox is set to revolutionize the audio domain. Whether you are a content creator, a multilingual communicator, or someone looking to enhance accessibility services, Voicebox is the ultimate tool for all your audio needs.
Frequently Asked Questions - FAQ's
What is Voicebox?
Voicebox is a groundbreaking generative AI model developed by Meta AI. It is designed for speech synthesis and is capable of generalizing across various speech-generation tasks. Unlike traditional speech synthesizers, Voicebox can create high-quality audio clips in multiple languages, perform noise removal, content editing, and style conversion.
How does Voicebox differ from traditional speech synthesizers?
Traditional speech synthesizers require specific training for each task and can only be trained on data that has been prepared expressly for that task. Voicebox, on the other hand, uses a novel method called Flow Matching and learns from raw audio and its accompanying transcription. This enables it to modify any part of a given sample and perform well across a variety of tasks.
In which languages can Voicebox synthesize speech?
Voicebox is capable of synthesizing speech in six languages: English, French, Spanish, German, Polish, and Portuguese.
What is Flow Matching and how does it contribute to Voicebox's capabilities?
Flow Matching is a method upon which Voicebox is built. It is an advancement on non-autoregressive generative models that can learn highly non-deterministic mapping between text and speech. This enables Voicebox to learn from varied speech data without the variations having to be carefully labeled. As a result, Voicebox can train on more diverse data and on a much larger scale.
Can Voicebox be used for audio editing?
Yes, Voicebox is capable of audio editing. Its in-context learning makes it adept at generating speech to seamlessly edit segments within audio recordings. It can resynthesize portions of speech corrupted by short-duration noise or replace misspoken words without having to re-record the entire speech.
What are the potential applications of Voicebox?
Voicebox has a wide range of applications including in-context text-to-speech synthesis, cross-lingual style transfer, speech denoising and editing, and diverse speech sampling. It can be used by content creators for audio editing, by multilingual communicators for seamless communication across languages, and in accessibility services to bring speech to people who are unable to speak.
Is Voicebox available for public use?
As of the information provided in the blog post, Meta AI has not made Voicebox publicly available due to potential risks of misuse. However, they have shared audio samples and a research paper detailing the approach and results achieved with Voicebox.
How does Voicebox handle the potential risks of misuse?
Meta AI recognizes the potential for misuse and unintended harm with Voicebox. They have built a highly effective classifier that can distinguish between authentic speech and audio generated with Voicebox to mitigate possible future risks.
Can Voicebox be used to generate synthetic data for training speech assistant models?
Yes, having learned from diverse in-the-wild data, Voicebox can generate speech that is more representative of how people talk in the real world. This capability can be used to generate synthetic data to help better train speech assistant models.
Where can I listen to samples of audio generated by Voicebox?
Meta AI has shared audio samples of Voicebox on their website. You can listen to the samples by visiting the official Voicebox page.
These FAQs provide a comprehensive understanding of Voicebox, its capabilities, applications, and availability. Voicebox represents a significant advancement in speech synthesis and has the potential to revolutionize the audio domain.